
銘柄情報はどのように管理していますか?

今回の記事では、このような質問にお応えします。

私はGoogleスプレッドシートで銘柄の管理をしています。
スプレッドシートを使うと、Webからデータを自動取得できるので、銘柄管理がかなり楽になります。
Excelでも半自動的に取得できるんですが、スプレッドシートの方が使いやすさは抜群です。
したがって今回は
記事の内容
- Googleスプレッドシートで自動的にWebのデータを取得する方法
をご紹介しようと思います。
目次
Googleスプレッドシートとは
-1024x576.jpg)
GoogleスプレッドシートはGoogle社が提供するWebベースの「表計算ソフト」です。
Webベースなので、インターネットとパソコンがあればどこからでもアクセスできるのが特徴です。
ブラウザでアクセスが可能なExcelだと思ってください。
自宅だけでなくネットカフェからでもアクセスできます。
またスプレッドシートは、WebベースなのでWebとの相性が抜群です。
このため、今回お伝えする「Webデータの自動取得」はスプレッドシートの得意分野になります。
Googleスプレッドシートを使って銘柄情報を自動取得する
Webから自動的にデータを取得する関数「IMPORTXML関数」

私はスプレッドシートで配当利回りなどを、Webから自動取得できるようにしています。
この自動化のために使っている関数は「IMPORTXML関数」です。
ITが苦手な人にとっては抵抗感のある名前ですが、覚えると結構簡単ですよ。
この記事では、使い方を丁寧に説明していますので、説明に従えば、誰でも簡単にできますよ!
「IMPORTXML関数」はWeb上のデータであれば、ほとんど自動取得できるようになっています。
配当利回りだけでなく、連続増配年数や株価など色んな情報を拾えるので、管理シートの幅が広がりますね。
IMPORTXML関数は「URL」と「XPath」で指定する

ここからはIMPORTXML関数の使い方のご紹介です。
今回は、Web上に公開されている「年間配当データ」の自動取得を一例に、IMPORTXML関数の使い方をご紹介しようと思います。
ブラウザはGoogle Chromeを使ってください。
コード(XPath)の取得が簡単になります。
取り上げるサンプル事例
「年間配当」をWeb上のデータから自動取得していきます。
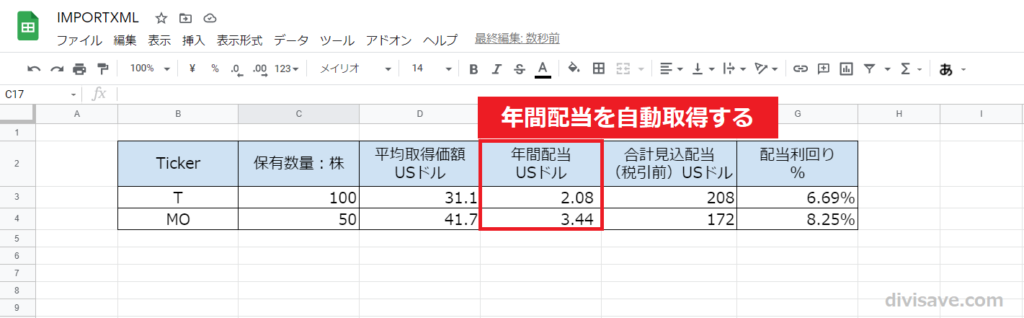
まず土台となる管理資料を作ります。
サンプルとしてTとMOを取り上げています。
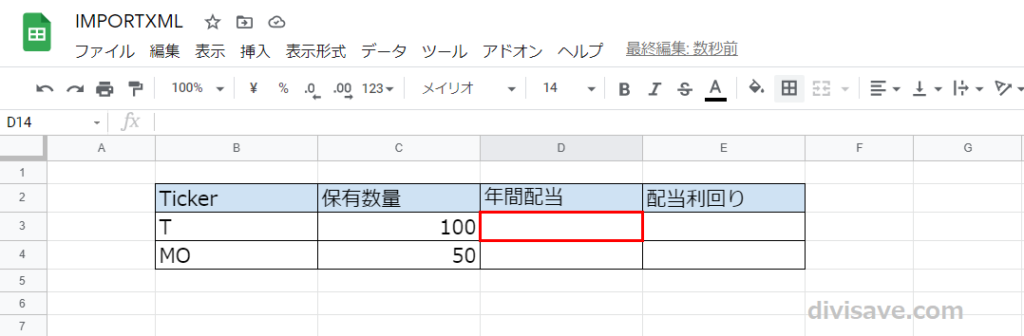
今回使う関数は「IMPORTXML関数」なので、上の図の赤枠のところに
数式
=IMPORTXML("URL","XPath")
と入力します。
上の数式をコピペしてもOKです。
「URL」と「XPath」は説明のために入力しているので、なくても良いです。その場合は「=IMPORTXML("","")」です。
実際に入力した画面がこんな感じです↓
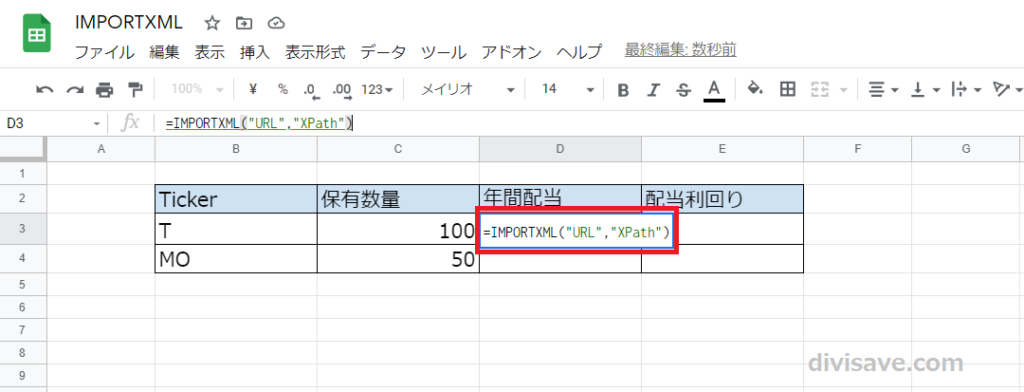
これでWebからデータを自動取得する土台ができたので、次は実際に拾ってくるデータを指定していきます。
IMPORTXML関数で「URL」を入力する

今回は米国個別株のTとMOの「年間配当」を取得してみようと思います。
実際に私が使っているStockNewsというサイトで試します。

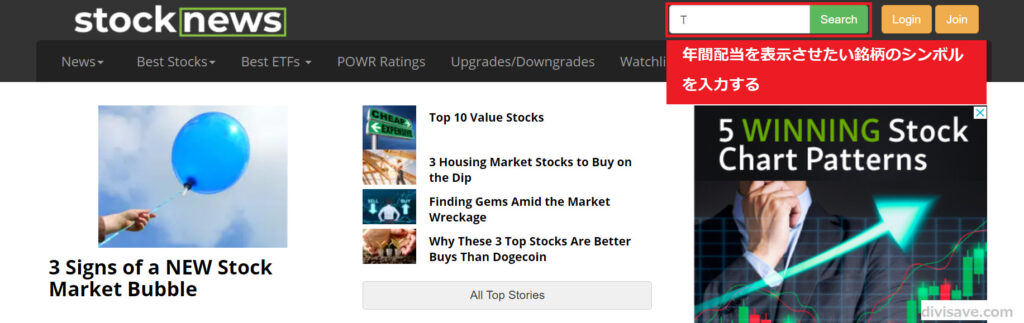
StockNewsのトップページ上部に検索窓があるので、そこに該当銘柄のTickerシンボルを入力し、「Search」をクリック。
対象の個別銘柄が表示されたら、次は中央の「Dividends」のタブをクリック。
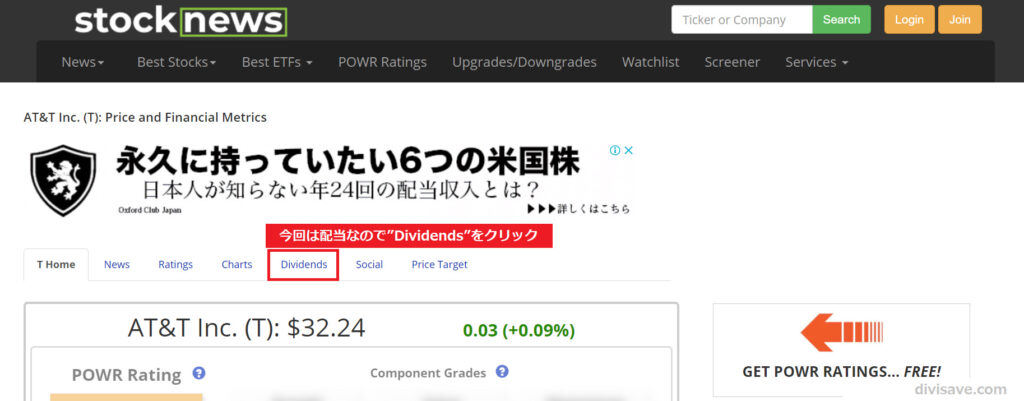
今回は年間配当額を取得するので、配当という意味の英語「Dividends」を選択しています。
すると、その銘柄の配当情報がつらつらと書いてあるので、中段くらいまでスクロールして「Annual Dividend」という項目を見つけます。
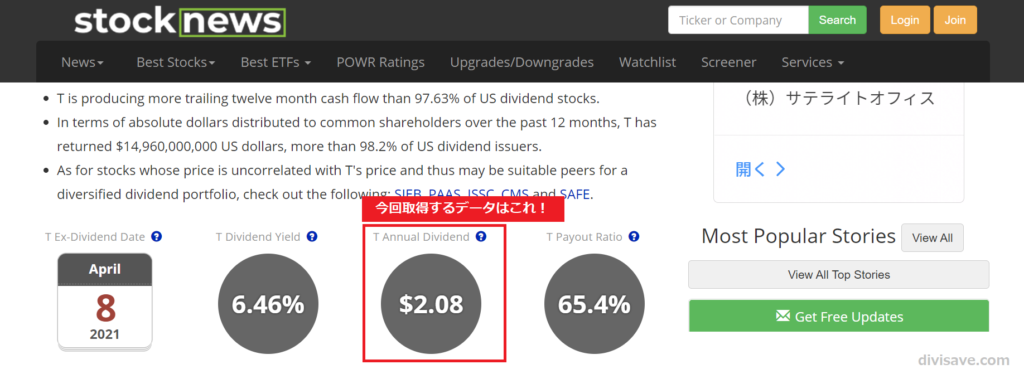
丸で囲われているやつですね。
これがその銘柄の年間配当額なので、これを確認後、スプレッドシートにデータ取得するための情報を入力していきます。
まずは「"URL"」です。
StockNewsのURLをコピーするため、DividendsをクリックしたあとのページでURLをコピーします。
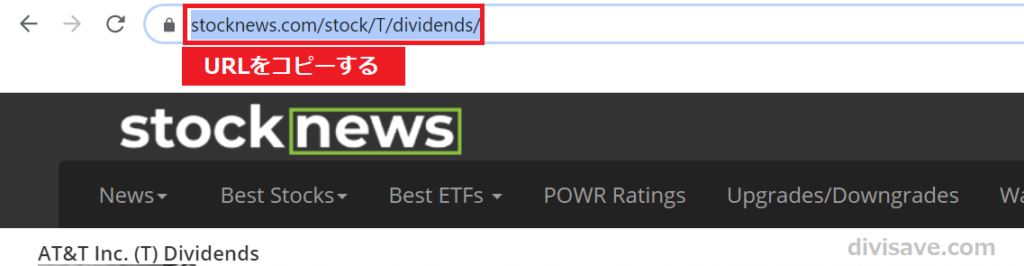
必ず「Dividendsをクリックしたあとのページ」のURLを取得してください。
ページを間違えるとうまくいきません。
次にスプレッドシートに戻って、IMPORTXML関数の 「URL 」の所に、先ほどコピーしたURLを貼り付けます。
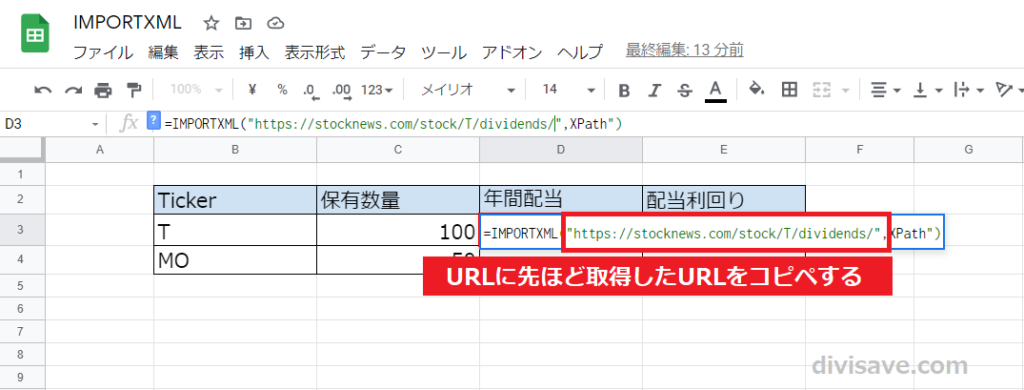
「=IMPORTXML("URL","XPath")」の「"URL"」ところです。
「"(ダブルクォート)」は2つとも残してくださいね。
これでデータの参照元ページの指定ができました。
ページのURLが変わると、データが取得できなくなるので、エラーが出たらまずはURLをチェックすると良いです。
IMPORTXML関数で「XPath」を入力する

次に自動的に取得したいデータを指定していきます。
データの取得のためにXPathを指定します。

XPathの取得は普通にやろうとすると難易度が高いのですか、Google Chromeを使うと驚くほど簡単にできます。
Google Chromeで表示したページ(先ほどURLをコピーしたStockNewsのページ)で「Ctrl + Shift + C」を同時に押します。
すると右側に何やらアルファベットの羅列が表示されます。
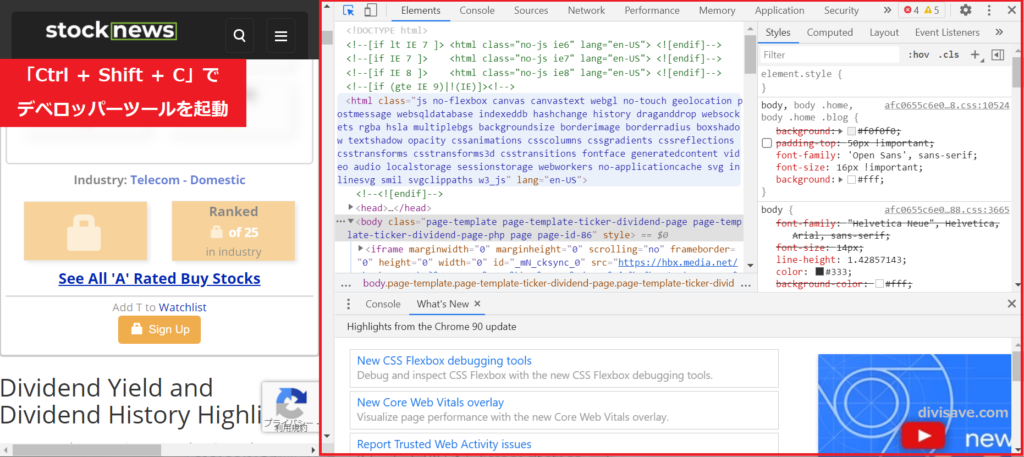
これはGoogle Chromeのデベロッパーツールと呼ばれるもので、そのWebページを構成するHTMLをツリー上に表示してくれています。
デベロッパーツールは今回特に覚えなくても良いので、以下説明する手順に従っていけば大丈夫です。
次に左側のWebページで、自動取得したいデータのところまでスクロールします。
今回は「年間配当データ」取得の自動化ですので、先ほど確認した「Annual Dividend」までスクロールします。
そして丸で囲われたAnnual Dividendをクリックしてみると、右側のデベロッパーツールが該当スクリプトまで勝手に移動してくれます。
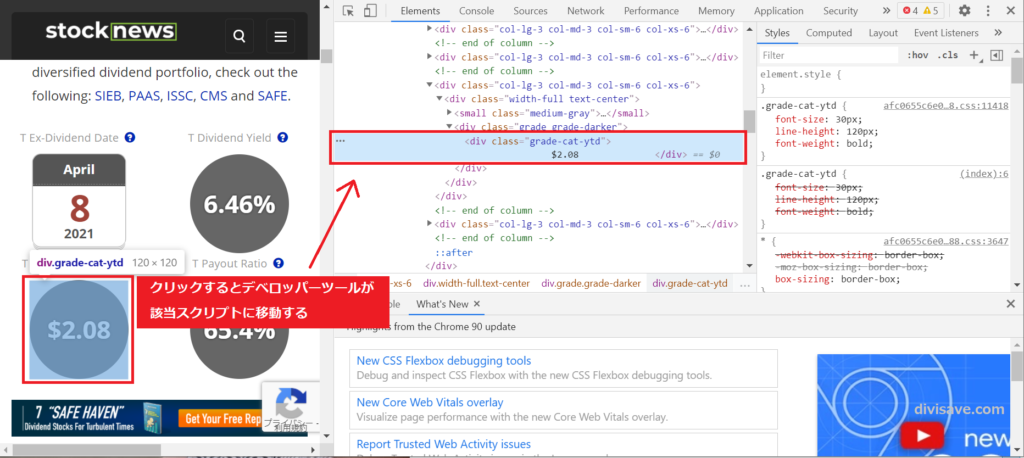
該当スクリプトはわかりやすいように色付けされています。
そのスクリプトを右クリック。「Copy」→「Copy XPath」の順にクリックします。
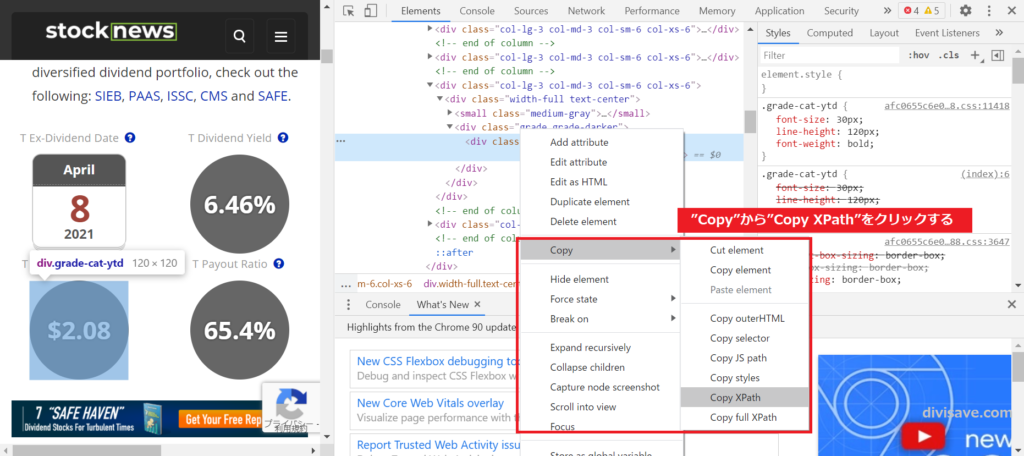
これでXPathのコピーが完了です。
簡単ですね。
スプレッドシートに戻り、IMPORTXML関数のXPathのところに先程コピーしたXPathを貼り付けます。
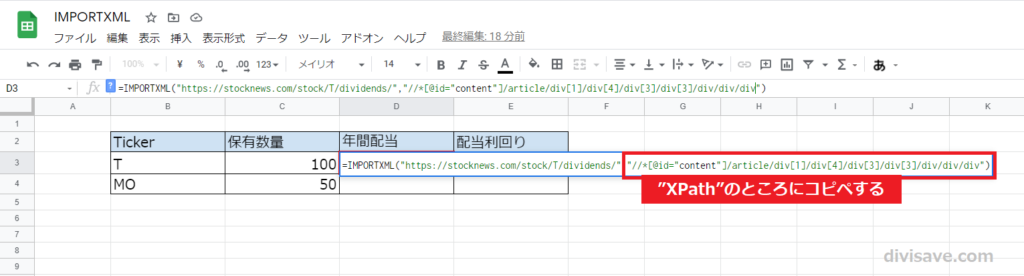
「=IMPORTXML("URL","XPath")」の「"XPath"」ところです。「"(ダブルクォート)」は2つとも残してくださいね。
ここで少し細工が必要になります。
スプレッドシートでは「”(ダブルクォート)」は数式の因数を区切る役割があるため、因数内で利用するとうまく機能してくれません。
このため、XPathに「”」があれば、それは「’(シングルクォート)」に変更してあげる必要があります。
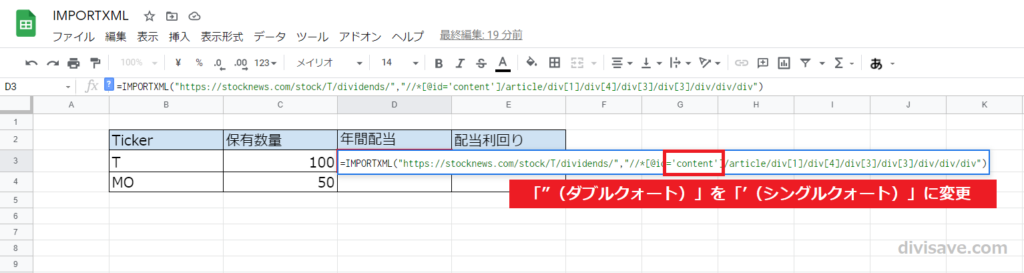
上の図のように「XPath」の中の「"」だけ変更してくださいね。
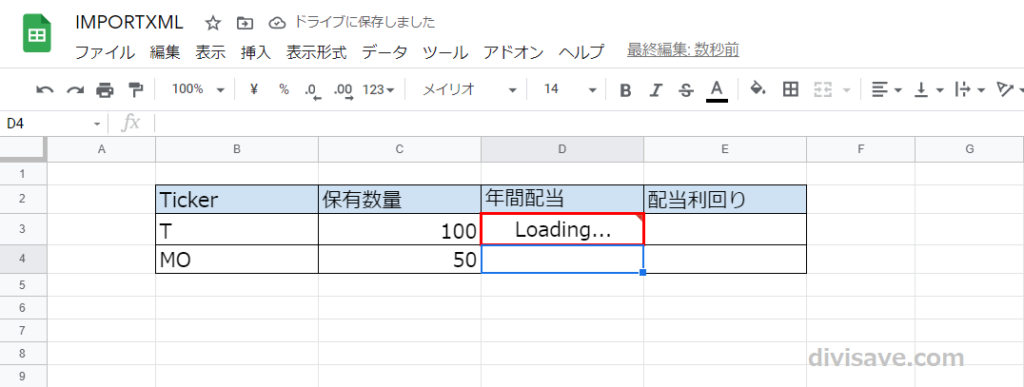
「”」を「’」に変更して数式を確定させると、スプレッドシートがWebからデータ取得を開始します。
最初は「Loading...」と表示され、
数秒待つと無事Webのデータが表示されるようになりました。
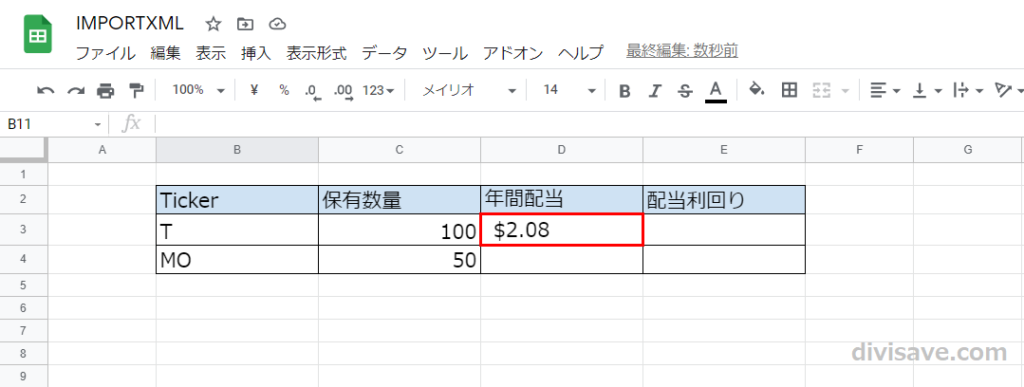
今回はTのAnnual Dividendを拾ってきたので「$2.08」が表示されました。
ほかの銘柄でも自動取得したい場合は、数式コピーが有効な場合もある

また今度はMOの年間配当額を取得します。
先ほどの作業を繰り返せば同じようにデータ取得が可能ですが、もう少し時短してみましょう。
多くのサイトは自動取得したいデータ項目が一緒であれば、XPathが同じである可能性が高いです。
なので、URLの変更だけで済むことが多く、時短になります。
先ほどTで取得した年間配当額の数式をコピーして、MOの行に貼り付けます。
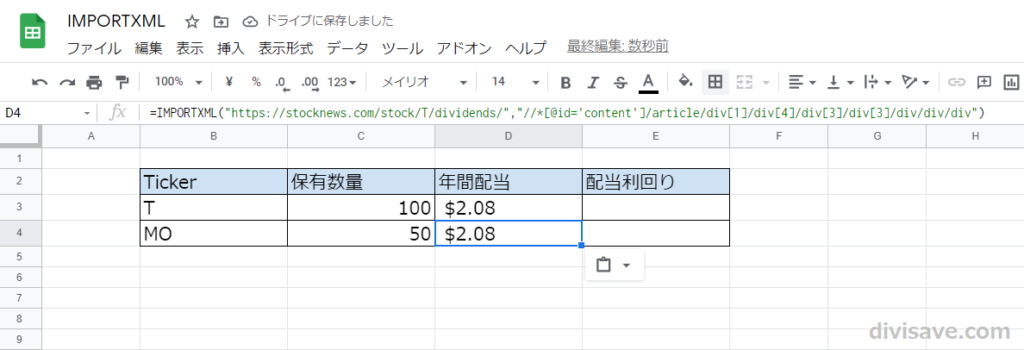
次にIMPORTXML関数のURL内「T」の部分を「MO」に書き換えます。
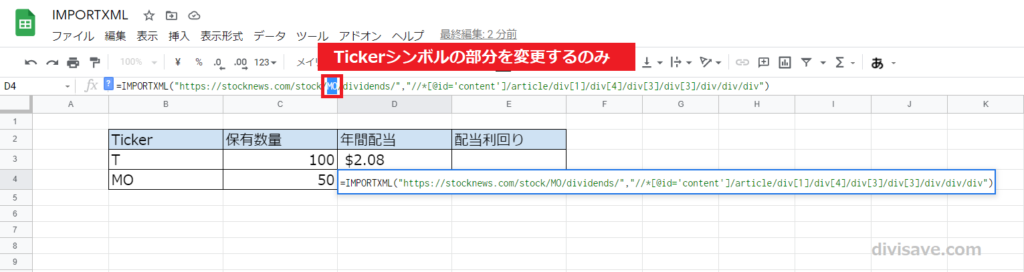
そこから数秒待ってみると、無事MOの年間配当額が表示されました。
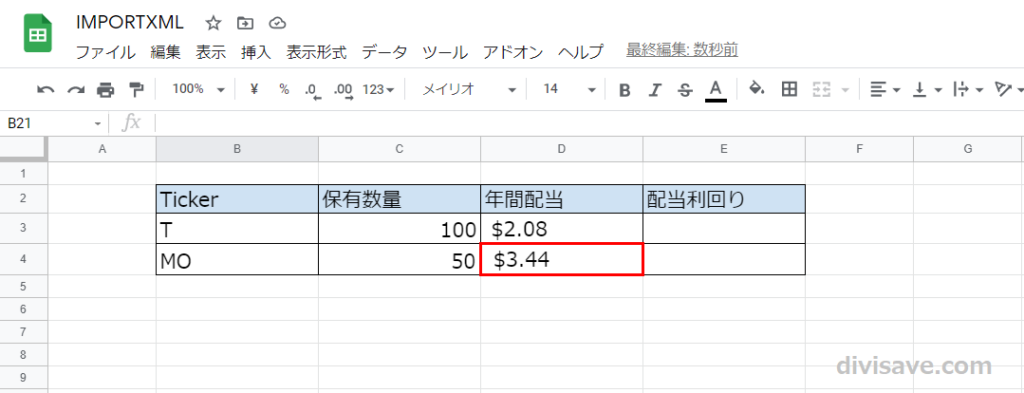
簡単ですね。
これでWebからのデータ取得が完了です。
Webから取得したデータを数式に変換して計算式に組み込む

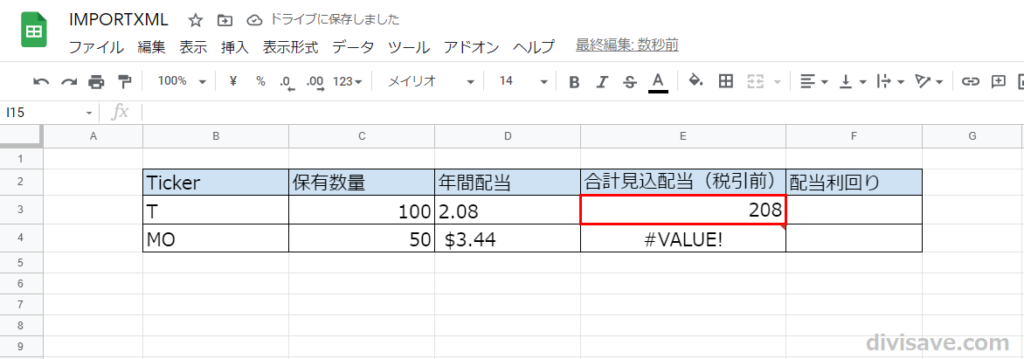
今回StockNewsから取得した年間配当額は、文字列「$」を含んでいました。
なので、以下の図のように計算式に組み込むとエラーになります。
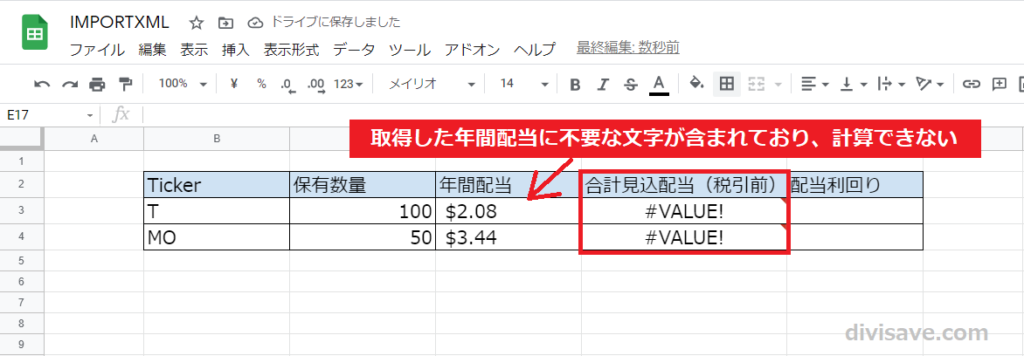
取得するデータによってはエラーにならないときもあります。
わざわざWebから拾ってきたのに計算に使えないのは不便なので、REPLACE関数を使って不要な文字列を削除します。
一般にREPLACE関数は、ある文字列を別の文字列に変換することを目的にしていますが、今回は変換後の文字列を「””」とすることで特定の文字列を消すという作業を行います。
数式
=REPLACE(変換したい文字列,変換開始位置,変換文字数,変換後の文字)
「変換したい文字列」のところに先ほどのIMPORTXML関数の数式をそのまま入力します。
今回のStockNewsから取得したデータは、「空白(スペース)」と「$」を含んでおり、それら2文字が文字列になっていました。
なので、開始位置は「1」、変換文字数を「2」に設定し、「変換後の文字」は「""」と入力します。
数式の左上にREPLACE関数反映後の結果が表示されるので、そこで確認すると確実です。
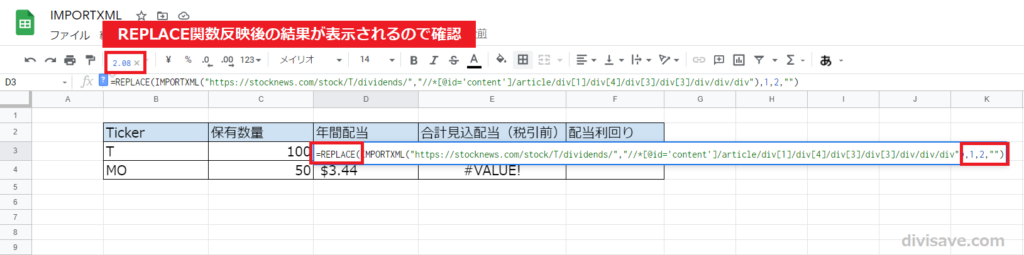
REPLACE関数を使用することで、データの文字列が消えて数値として認識されるようになりました。
その結果、合計見込配当が計算されています。
MOでも同様にREPLACE関数を使って不要な文字列を消して、必要な項目を追加するなど体裁を整えると、以下のように銘柄のデータ取得が自動化された管理表の完成です。
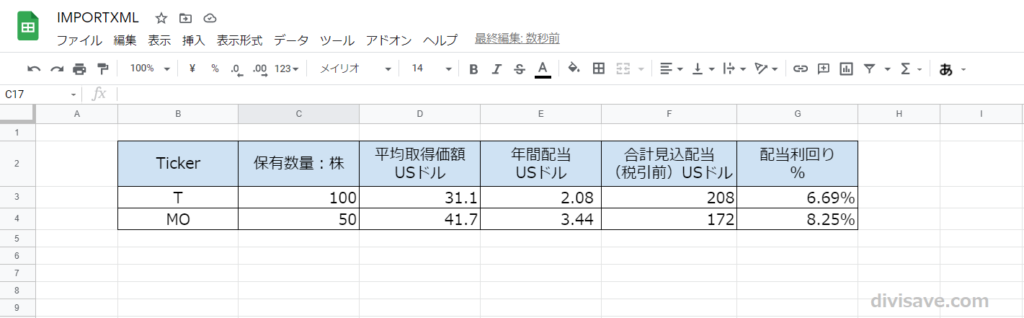
Webからデータを自動取得してくれるので、例えばTが増配して年間配当額が2.10ドルになった場合には、(参照元ページのデータが更新されれば)管理表の年間配当が自動で更新されるようになります。
こうすることでかなり手間が削減されますね。
みなさんも是非挑戦してみてください。
管理が驚くほど楽になりますよ。
Googleスプレッドシートを勉強したい方向けの教材
今回の記事は、普段スプレッドシートを使っていない人にとっては、難しい内容だったかもしれません。
使い方はExcelとほとんど同じなので、全く使えないものではないのですが…。
それでもやっぱり難しい。
そんな人のために、スプレッドシートを基礎から学べる教材をご紹介しておきます。
文系女子と学ぶ!Googleスプレッドシート
タイトルの通り、ITに疎い文系女子でもスプレッドシートを扱えるようになることを目的に作られた本です。
なのでほかの教材よりもつまずきにくい作りになっています。
私のおすすめの本です。
はじめてのGoogleスプレッドシートの教科書2021
スプレッドシートを勉強しはじめるときの定番教材です。
どんな本を買えばよいか、皆目検討もつかないという方はこの本から、学ばれると良いかもしれません。
これらの本を活用してスプレッドシートに慣れていきましょう。
自動化するならExcelよりもGoogleスプレッドシートですので、ぜひご検討を!
